
കീമാജിക്ക് 2.0 ന്റെ പ്രിവ്യൂ പതിപ്പ് ഇറങ്ങിയിട്ട് കുറച്ച് നാളായി. വിസ്റ്റ മുതൽ 10 വരെയുള്ള വിൻഡോസുകളിൽ മറ്റ് പോഗ്രാമുകൾ ഇൻസ്റ്റാൾ ചെയ്യാതെ തന്നെ കീമാജിക്ക് ഉപയോഗിക്കാം എന്ന മെച്ചമുണ്ട്. കൂടാതെ, മുൻപുള്ളതിൽ നിന്നും വ്യത്യസ്തമായി 32 ബിറ്റിനും 64 ബിറ്റിനും ഒരേ കീമാജിക്ക് തന്നെ മതി. മുൻപ് അത് സാധ്യമല്ലായിരുന്നു.
പുതിയ കീമാജിക്ക് ഇവിടെനിന്നും ഡൗൺലോഡ് ചെയ്യാം. KeyMagic-v2.0Pre-4 ആൺ നിലവിൽ ലഭ്യമായിരിക്കുന്നത്. കൂടുതൽ മെച്ചപ്പെടുത്തുലുകൾ നടക്കുന്ന് മുറയ്ക്ക് പുതിയ പതിപ്പുകൾ ഇറങ്ങും.
കീമാജിക്ക് ഇൻസ്റ്റാൾ ചെയ്താൽ മലയാളം കീബോർഡുകൾ അതിലുണ്ടാവില്ല. മലായാളം മൊഴി രീതിയനുസരിച്ചുള്ള കീബോർഡ് ലഭിക്കാനായി താഴെ നൽകിയിരിക്കുന്നതുപോലെ ചെയ്യുക.
- ആദ്യം ഈ ലിങ്കിൽ പോയി “Malayalam-Mozhi-2.0.km2” എന്ന ഫയൽ ഡൗൺലോഡ് ചെയ്യുക.
- ശേഷം കീമാജിക്കിന്റെ സെറ്റിങ്ങ്സ് വിൻഡോയീൽ ചെന്ന് “Add” ബട്ടൺ അമർത്തി “Malayalam-Mozhi-2.0.km2” ഫയൽ തിരഞ്ഞെടുക്കുക.
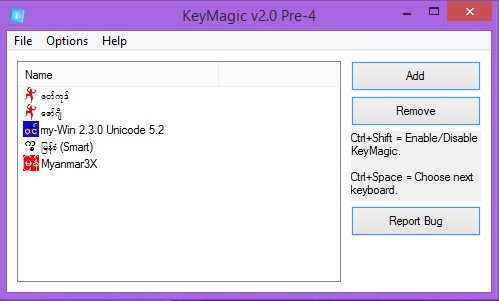
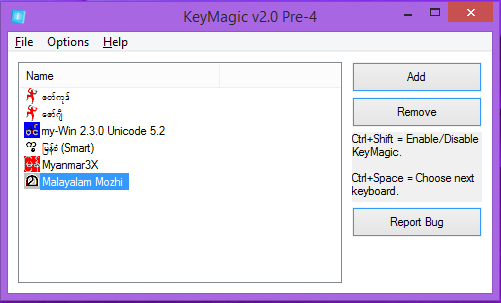
- ഇപ്പോൾ മലയളാം മൊഴി കീബോർഡ് മറ്റ് കീബോർഡുകളൊടൊപ്പം കാണാം.
സ്വതേയുള്ള മ്യാന്മർ കീബോർഡുകൾ അവശ്യമില്ലെങ്കിൽ കളയാവുന്നതാണ്.
കീമാജിക്ക് പ്രോഗ്രാമുമായി ബന്ധപ്പെട്ട പ്രശ്നങ്ങൾ സെറ്റിങ്സ് വിൻഡോയിലെ “Report Bug” ബട്ടൺ ക്ലിക്ക് ചെയ്തുവരുന്ന പേജിൽ സമർപ്പിക്കാം.
മലയാളം ടൈപ്പിങ്ങ് രീതി മെച്ചപ്പെടുത്താനുള്ള നിർദ്ദേശങ്ങൾ ബോഗ് പോസ്റ്റിനുള്ള കമന്റായോ, ഈമെയിൽ അയക്കുകയോ, ഫേസ്ബുക്കിൽ പോസ്റ്റ് ചെയ്ത് എന്നെ ടാഗ് ചെയ്യുകയോ ചെയ്ത് അറിയിക്കക.
Leave a Reply